


 />i
/>iThis is part Ten of the continuing series on two-filter document culling. This is very important to successful, economical document review. Please read part nine before this one.
Three Kinds of Second Filter Probability Based Search Engines
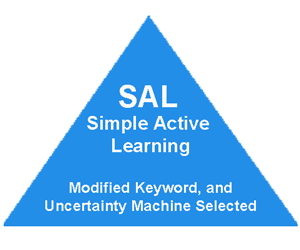 After the first round of training (really after the first document is coded in software with continuous active training), you can begin to harness the AI features in your software. You can begin to use its probability ranking to find relevant documents. There are currently three kinds of ranking search and review strategies in use: uncertainty, high probability, and random. (I use all three kinds, including other non-predictive coding searches. This combined approach can be considered a fourth multimodal method.)
After the first round of training (really after the first document is coded in software with continuous active training), you can begin to harness the AI features in your software. You can begin to use its probability ranking to find relevant documents. There are currently three kinds of ranking search and review strategies in use: uncertainty, high probability, and random. (I use all three kinds, including other non-predictive coding searches. This combined approach can be considered a fourth multimodal method.)
The uncertainty search, sometimes called SAL for Simple Active Learning, looks at middle ranking documents where the code is unsure of relevance, typically the 40%-60% range. The high probability search looks at documents where the AI thinks it knows about whether documents are relevant or irrelevant. You can also use some random searches, if you want, both simple and judgmental, just be careful not to rely too much on chance.
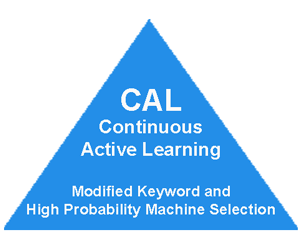 The 2014 Cormack Grossman comparative study of various methods has shown that the high probability search, which they called CAL, for Continuous Active Learning using high ranking documents, is very effective. Evaluation of Machine-Learning Protocols for Technology-Assisted Review in Electronic Discovery, SIGIR’14, July 6–11, 2014. Also see: Latest Grossman and Cormack Study Proves Folly of Using Random Search For Machine Training – Part Two.
The 2014 Cormack Grossman comparative study of various methods has shown that the high probability search, which they called CAL, for Continuous Active Learning using high ranking documents, is very effective. Evaluation of Machine-Learning Protocols for Technology-Assisted Review in Electronic Discovery, SIGIR’14, July 6–11, 2014. Also see: Latest Grossman and Cormack Study Proves Folly of Using Random Search For Machine Training – Part Two.
My own experience also confirms their experiments. High probability searches usually involve SME training and review of the upper strata, the documents with a 90% or higher probability of relevance. The exact percentage depends on the number of documents involved. I may also check out the low strata, but will not spend very much time on that end. I like to use both uncertainty and high probability searches, but typically with a strong emphasis on the high probability searches. And again, I supplement these ranking searches with other multimodal methods, especially when I encounter strong, new, or highly relevant type documents.
Sometimes I will even use a little random sampling, but the mentioned Cormack Grossman study shows that it is not effective, especially on its own. They call such chance-based search Simple Passive Learning, or SPL. Ever since reading the Cormack Grossman study I have cut back on my reliance on any random searches. You should too. It was small before, it is even smaller now. This does not mean sampling does not still have a place in documents review. It does, but in quality control, not in selection of training documents. See eg. ZeroErrorNumerics.com and Introducing “ei-Recall” – A New Gold Standard for Recall Calculations in Legal Search.